RDB와 SQL은 오랜기간 동안 개발자들의 동반자였고, 끊임없이 개선되고 발전해왔으나 수십년의 시간이 지나면서 많은 문제점이 노출되었습니다.
가장 큰 문제는 두가지 형태로 나타났는데
1. 비정형 데이터의 저장
2. 부자연스러운 탐색
이를 해결하기 위해 NoSQL (not only sql) 이 등장하게 되는 것은 자연스러운 현상이였습니다.
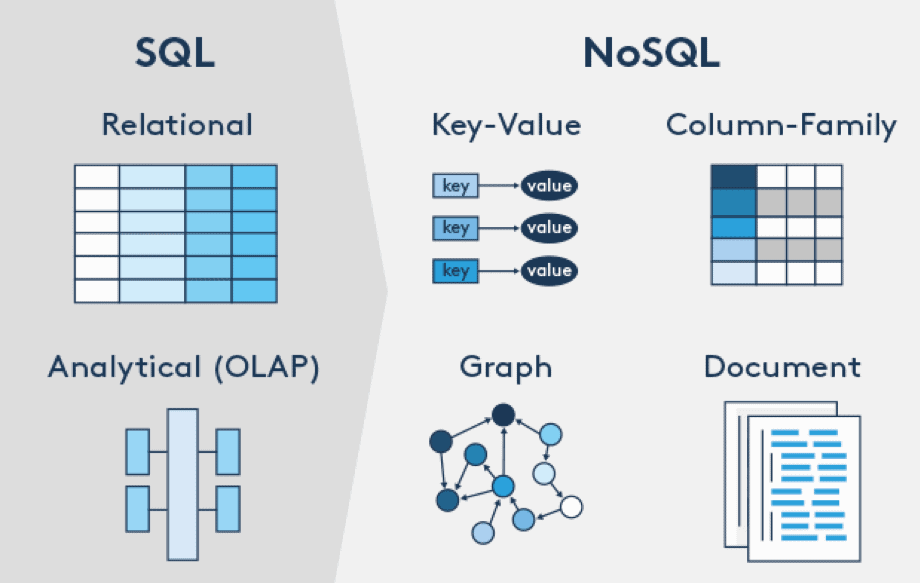
수 많은 NoSQL 중에서 오늘 이야기해볼 대상은 Graph Database입니다.
아이디어는 간단합니다.
기존의 SQL에서는 데이터간의 관계를 FK로 정의하고 JOIN 을 통해 데이터를 가져올수 있었습니다
그러나 Graph Database 세계에서는 관계라는 부분을 더욱더 강화하여 관계를 데이터와 동격으로 승격시킨 방식이라고 할 수 있습니다.
예를들어 관계자체가 검색조건이 되며 예외조건이 됩니다.
또한 관계가 값을 가지도록 할 수 있습니다.
뿐만 아니라 관계를 통한 재귀검색이 가능합니다.
이렇게 되므로서 얻는 이득은 무궁무진한데 개인적으로 가장 큰 장점은 현실의 구현이 자연스러워 진다는 것입니다.
더 간단히 말하면 우리의 뇌가 사고하는 방식은 기존의 SQL보다는 Graph 에 더 가깝습니다.
단적으로 우리가 I go to school 이라는 말을 뱉을때
I(명사) + go(동사) + to(부사) + school(목적어) 라고 풀어서 생각하지않고 숨쉬듯 자연스럽게 내뱉을 수 있는것은 바로 연결된 사고를 하고 있는 것입니다.
인간은 연결된 사고를 하지 못하면 생각보다 많은 곳에서 머뭇거리게 되는데요
그렇기에 기존의 SQL을 전공자가 아닌사람에게 설명하기 어려운 것에 반해 GRAPH 방식의 언어는 어린아이에게도 설명하기 쉬울정도로 직관적입니다.
MATCH (minsu:Person) -[:hasFriend]-> (friends:Person)
WHERE minsu.name = '민수'간단하게 Cypher 문법을 보면 이건 언어가 아니라 그림같은 느낌을 받으실수 있습니다.
이것을 가능하도록 만드는 것은 [:hasFriend] 란 관계입니다.
SELECT friends.*
FROM persion minsu
JOIN persion friends ON minsu.friend_id = persion.persion_id
WHERE persion.name = '민수'반면 SQL은 개발자눈에는 너무 쉽게 보일수 있으나 생각을 자연스럽게 작성하는 것이 아닌 개발자로서 뇌를 한번 자극시켜줘야합니다.
고로 Graph SQL을 접근할때는 SQL을 접근하던 Grid 형태로의 사고방식을 잠시 접어두고 평범한 한명의 인간으로 돌아올 필요가 있습니다.
소개는 여기까지하고 다음 시간에는 좀더 자세히 알아보겠습니다.
'개발 > GraphDatabase' 카테고리의 다른 글
| 4. Repeat 과 Emit (0) | 2023.06.12 |
|---|---|
| (번외) Neptune 에서 Spring Data Neo4j 쓰는 법 (0) | 2023.06.11 |
| 3. 서울에서 Vertex 서방 찾기 (0) | 2023.06.10 |
| 2. Vertex와 Edge (0) | 2023.06.10 |
| 1. Gremlin과 Cypher (1) | 2023.05.20 |